
The image above was created using AI. More specifically, this was the first image generated by Runway, when given the prompt “Amazon Fake Review Detector”.
As a quick reminder of my previous post: for my final project in my Applied AI in Python course, I wanted to address a real-world issue that is extremely prevalent today. The problem I chose to try and solve was fake Amazon reviews, by testing a whole bunch of sklearn ML text classifiers, and finding the one that worked best.
To continue from last blog post:
The very first thing we needed to do to even start this project was to find a good dataset with both computer generated and human generated reviews. Fortunately, I found one that has over 20,000 labelled reviews of each type, which is perfect for this project. So I opened it up:

That’s actually really good! But to circle back to the problem I’m actually trying to solve, I want to be able to detect whether a review is human or computer generated, regardless of the product category or out-of-five star rating. To remove this information from the dataset, I read this file as a pandas dataframe, and dropped the columns “category” and “rating”:
df = pd.read_csv(url)
df = df.drop(labels=['category', 'rating'], axis=1)
Now, the dataset looks like this:
Let’s print a more detailed description:
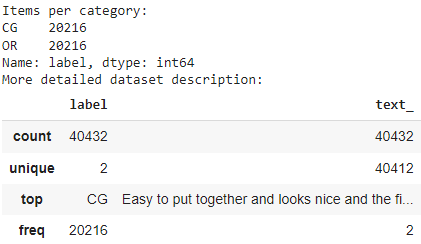
print("Items per category:")print(df['label'].value_counts())print("More detailed dataset description:")df.describe()
This gives us:
Now, we need to split our data into training and validation sets. The Sci-kit Learn python library already has a function for this:
from sklearn.model_selection import train_test_split X_training, X_val, Y_training, Y_val = train_test_split(df['text_'], df['label'], test_size=0.2)
Lastly, we can convert out text data using a TF-IDF vectorizer. A TF-IDF (Term frequency-inverse document frequency) vectorizer is “a measure of originality of a word by comparing the number of times a word appears in document with the number of documents the word appears in.” The Sci-kit Learn python library also already has a function for this:
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer()X_training_tfidf = vectorizer.fit_transform(X_training)X_val_tfidf = vectorizer.transform(X_val)
We now import all of the models that we will be using from the sklearn library. We will be testing the following classifiers: Logistic Regression, Support Vector Machine, Decision Tree, Random Forest, Extra Trees, K-Nearest Neighbors, Adaboost, Gradient Boosting, and Bagging.
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import GradientBoostingClassifier
lg = LogisticRegression(penalty='l1',solver='liblinear')
sv = SVC(kernel='sigmoid',gamma=1.0)
dtc = DecisionTreeClassifier(max_depth=5)
knn = KNeighborsClassifier()
rfc = RandomForestClassifier(n_estimators=50,random_state=2)
etc = ExtraTreesClassifier(n_estimators=50,random_state=2)
abc = AdaBoostClassifier(n_estimators=50,random_state=2)
bg = BaggingClassifier(n_estimators=50,random_state=2)
gbc = GradientBoostingClassifier(n_estimators=50,random_state=2)
To evaluate the performances of each of these classifiers, we define a prediction function that takes a model, the training and testing data, and outputs the accuracy and F1 scores of the model:
def prediction(model, X_train, X_test, y_train, y_test):
model.fit(X_train, y_train)
pr = model.predict(X_test)
acc_score = metrics.accuracy_score(y_test, pr)
f1 = metrics.f1_score(y_test, pr, average="binary", pos_label="CG")
return acc_score, f1
We create dictionaries to store these scores for each classifier, and also a dictionary to name this dictionary’s keys:
acc_score = {}
f1_score = {}
clfs = {
'LR': lg,
'SVM': sv,
'DTC': dtc,
'KNN': knn,
'RFC': rfc,
'ETC': etc,
'ABC': abc,
'BG': bg,
'GBC': gbc,
}
And finally, we run the prediction function on each of these algorithms, and print out the results:
for name, clf in clfs.items():
acc_score[name], f1_score[name] = prediction(clf, X_train_tfidf, X_test_tfidf, y_train, y_test)
print(acc_score)
print(f1_score)
For the accuracy scores, we get:
{'LR': 0.8972424879436132, 'SVM': 0.8847533077779152, 'DTC': 0.7299369358229257, 'KNN': 0.5672066279213552, 'RFC': 0.8763447508346729, 'ETC': 0.8973661431927785, 'ABC': 0.8284901694076914, 'BG': 0.8559416347223939, 'GBC': 0.8225547174477557}
For the F1 scores, we get:
{'LR': 0.8972678946717765, 'SVM': 0.8855880186594647, 'DTC': 0.7136113296616837, 'KNN': 0.6959694232105629, 'RFC': 0.8808104886769965, 'ETC': 0.900788907482668, 'ABC': 0.8301701971348108, 'BG': 0.8600936711901045, 'GBC': 0.8190644307149162}
And so we see that Logistic Regression actually performs the best in both categories!
Now, we build a very simplistic user interface that allows the user to copy+paste their own reviews into the Logistic Regression classifier:
model = LogisticRegression(penalty='l2', intercept_scaling=1, class_weight=None, verbose=0, warm_start=True) # Defining the model
model.fit(X_train, y_train)
print("How many reviews would you like to verify?")
for i in range (int(input())): # User inputs reviews
print("Please input review", i+1, ":")
input_review = input()
vect_input=vectorizer.transform([str(input_review)])
if model.predict(vect_input) == ['CG']:
print("The review", input_review[0], "...", input_review[len(input_review)-1], "is most likely Computer Generated.")
if model.predict(vect_input) == ['OR']:
print("The review", input_review[0], "...", input_review[len(input_review)-1], "is most likely Human Generated.")
And it works! I would even highly recommend that you, the reader, copy this code and try it out on your own Amazon reviews. Cheers!
