The above image was fourth image generated by Stable Diffusion when inputted “Counting Letters for Every Word”.
So far, in my search of finding the optimal word for the game Wordle, I have developed a sort of brute-force method of counting how often each letter appears in each word and in each place. The algorithm was pretty simple: “Direct Intersection” refers to letters that are congruent and are located in congruent positions within a word; comparing the words “apple” and “angle” results in three direct intersections: “a__le”. “Indirect Intersection” to refer to letters that appear in both words, but are not in the same position; comparing the words “intel” and “tenet”, we have indirect intersections for “n”, 2″t”, 2″e”. Notice that despite an e being a direct intersection, it is also an indirect intersection. The algorithm essentially compared every word to every other word by directly checking if a certain letter in a certain place was the same, and if the letter was present in both words. However, this method entailed hundreds of billions of direct comparisons (197,688,192,000 to be exact), which eventually led to program force stops. So it solved the problem, but in the worse way possible. So it really didn’t.
Instead, I decided to try a different strategy: This time, instead of directly counting the number of intersections between two given words, I would count how many times each letter appeared in each place, then aggregate the information to assign a score to each word. Then, using this score, I could rank words and find the best word. And this solves a major issue: efficiency; instead of having to do hundreds of billions of comparisons, the program would only need to do 159,200 comparisons, which is quite literally a million (1,241,760 to be exact) times better.
The process to set this up was quite simple; a lot of the base setup code could be recycled from the previous project:
f = open("words_alpha.txt")
bigChunkofText = f.read()
words = bigChunkofText.split('\n')
words_5 = []
for word in words:
if len(word)==5:
words_5.append(word)
Gave me the list of all 5 letter words. Now, to test how many times each letter appears, I created a list of all the letters in the spaghettiest way possible:
Letterchecks = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
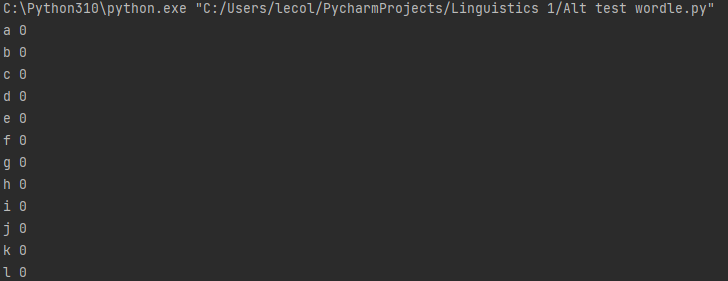
dict = {}
for letter in Letterchecks:
dict[letter] = 0
I also initialized a dictionary, so we could systematically use the terms in Letterchecks as keys in the dictionary, and count in that way (starting from 0). Just to test, we print it:
It works! We now set up the framework:
for letter in Letterchecks:
for word in words_5:
for lettercheck in range(0, 4):
if word[lettercheck] == letter[0]:
dict[letter] += 1
for letter in sorted(dict, key=dict.get, reverse=True):
print(letter, dict[letter])
Which results in:
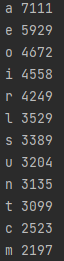
Wow! We found how many times each letter appears total!
